
Improving the signal-to-noise ratio in group conversations with Signia Integrated Xperience and RealTime Conversation Enhancement
Created Updated
Written by Niels Søgaard Jensen, Cecil Wilson, Homayoun Kamkar Parsi, Brian TaylorAbstract
With the introduction of RealTime Conversation Enhancement (RTCE), Signia Integrated Xperience (IX) offers a completely new way of addressing hearing aid wearers’ problems when participating in group conversations in background noise. The ability to improve the signal-to-noise ratio (SNR) in a group conversation situation – a necessary precondition for understanding speech – was investigated in a series of technical measurements in which Signia IX was compared to four competitors. Using the Hagerman phase-inversion method in a test arrangement simulating a typical group conversation in background noise, it was possible to measure the aided output SNR. The results showed a clear advantage for RTCE, with Signia IX providing an overall output SNR 4.1 dB better than the nearest competitor. Additionally, Signia IX offered a clear SNR advantage for both a frontal and a lateral talker in this test arrangement. These results suggest that Signia IX can provide a substantial benefit for the wearer, compared to competitor’s hearing aids, in group conversions in noise.
Introduction
One of the main goals of developing Signia Integrated Xperience (IX) with RealTime Conversation Enhancement (RTCE) has been to improve the IX wearers’ ability to excel in one of the most challenging communication situations: Group conversation in background noise. Signia’s RTCE has been meticulously designed to address the problems experienced in this type of listening situation, which is known to cause enormous challenges for many types of hearing aid processing, including conventional beamforming and other noise reduction approaches.
Detailed information on the background and function of RTCE are provided in Jensen et al. (2023). A simplified illustration of RCTE is shown in Figure 1. As indicated in the left part of the figure, RTCE works in combination with the Augmented Focus split processing, introduced on the Signia Augmented Xperience (AX) platform (Branda, 2021). The split processing facilitates the unique RTCE three-stage approach, which is illustrated in Figure 1.
In the first stage, Analyze, the complete conversation layout is determined when relevant speech is detected in the front hemisphere. The analysis includes localization of the talkers involved in the conversation and assessment of the conversation dynamics. In the second stage, Augment, advanced binaural processing is used to create three independent focus streams, which are added to the existing focus stream from the split processing, allowing talkers in the conversation to be enhanced, while background noise is processed independently as a surrounding stream. In the third stage, Adapt, the streams are combined to create a conversation sphere that changes adaptively according to changes in the conversation layout, e.g., when conversation partners take turns speaking, when they move or when the wearer turns their head.
Jensen et al. (2023) presented data from a study performed at Hörzentrum Oldenberg in Germany where the performance of Signia IX with RTCE was investigated using different implementations of a standardized speech-in-noise test. In tests simulating both a one-on-one conversation and a more challenging group conversation with multiple talkers, the study results showed significant benefits in speech understanding of Signia IX with RTCE activated compared to a setting in which RTCE was turned off. In a test simulating a group conversation scenario, 95% of the participants showed improved speech-in-noise performance with RTCE.
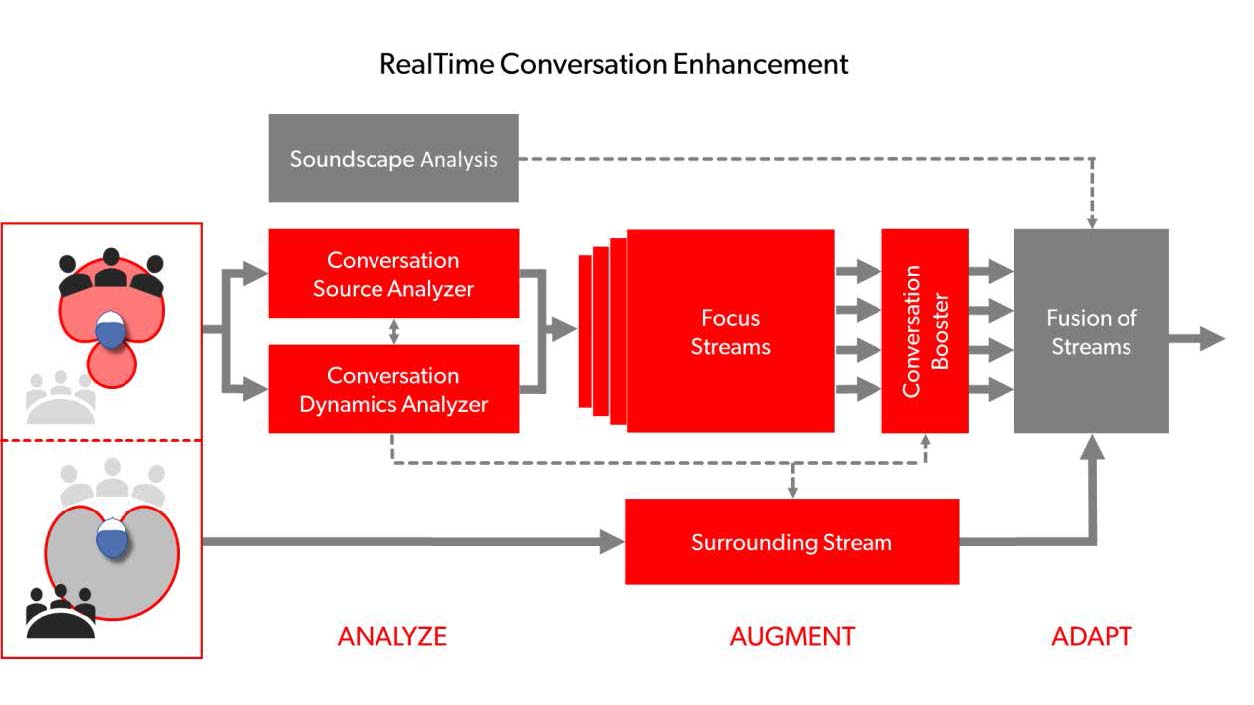
Figure 1. Simplified diagram showing the functionality of the RealTime Conversation Enhancement technology. Bold lines and arrows indicate the flow of the streams, while thin dotted lines and arrows indicate control paths.
A clinically relevant question is, how does RTCE with its multi-stream architecture perform compared to other hearing aids with single stream processing? Specifically, we wanted to answer this question: What is the signal-to-noise ratio (SNR) benefit of Signia IX in a group conversation scenario compared to the benefit of products from competitors? The improvement in SNR is important because it is an essential prerequisite for speech understanding improvements in noisy situations. By using advanced measurement techniques, the processed SNR can be assessed at the output of the hearing aid, and accordingly, the differences between hearing aid processing approaches can be evaluated under well-controlled conditions.
In the following, we report on a benchtop investigation, in which Signia IX was compared to four different competitor products. The primary purpose of the investigation was to assess SNR differences across hearing aids in a simulated group conversation in background noise. First, we explain our measurement methods, and then we present and discuss our results.
Methods
Hagerman method
The investigation was based on the Hagerman phase-inversion technique originally proposed by Hagerman & Olofsson (2004). This technique is widely recognized as a way to assess noise reduction systems in hearing aids when speech and noise are present at the same time. The methodology builds on the basic fact that if two identical versions of the same sound signal are summed, they will cancel each other if the phase of one of the signals is inverted (shifted by 180°). This means that if a speech signal is mixed with a noise signal at the input of a hearing aid, and a recording of the combined signal is done at the output of the hearing aid, it is possible, by repeating the recording with the phase of the noise signal being inverted, to obtain a ‘clean’ version of the speech signal by summing the two recorded signals. Thus, it is possible to investigate the processed speech and the processed noise (in isolation) at the hearing aid’s output. Consequently, by averaging across the clean signals, it is possible to provide a precise estimate of the output SNR experienced by the hearing aid wearer.
There are some requirements which need to be fulfilled for this technique to work. Since it is based on a series of consecutive recordings, it is important that the hearing aids work in exactly the same way for all recordings. This means that the hearing aids are in the same stable working condition before each recording is started, and that they are subjected to the exact same stimuli in all recordings. In practice, the hearing aids should be exposed to a controlled (stable) input sound for as long as it takes to activate relevant features and reach a stable processing state before the recording is started. The Hagerman technique also requires that the hearing aid processing does not change the phase of the signal, since this would eliminate the effect of the phase inversion. Since some special features like automatic feedback cancellation and frequency compression typically involve some (unpredictable) changes of the phase, such features need to be turned off.
Measurement setup
In this investigation, we used an implementation of the Hagerman method, which was inspired by the version employed by Aubreville & Petrausch (2015). The measurement setup, shown in Figure 2, was established in a sound treated room and included a KEMAR manikin (in the center of the setup) and four loudspeakers positioned at a distance of 1 m. Different sections of the International Speech Test Signal (ISTS) (Holube et al., 2010) were presented from two loudspeakers at 0° and 315° at a level of around 76 dBA, while a background noise consisting of a recording made in a busy cafeteria mixed with pink noise was presented from two loudspeakers at 135 and 225° at a level of around 72 dBA.
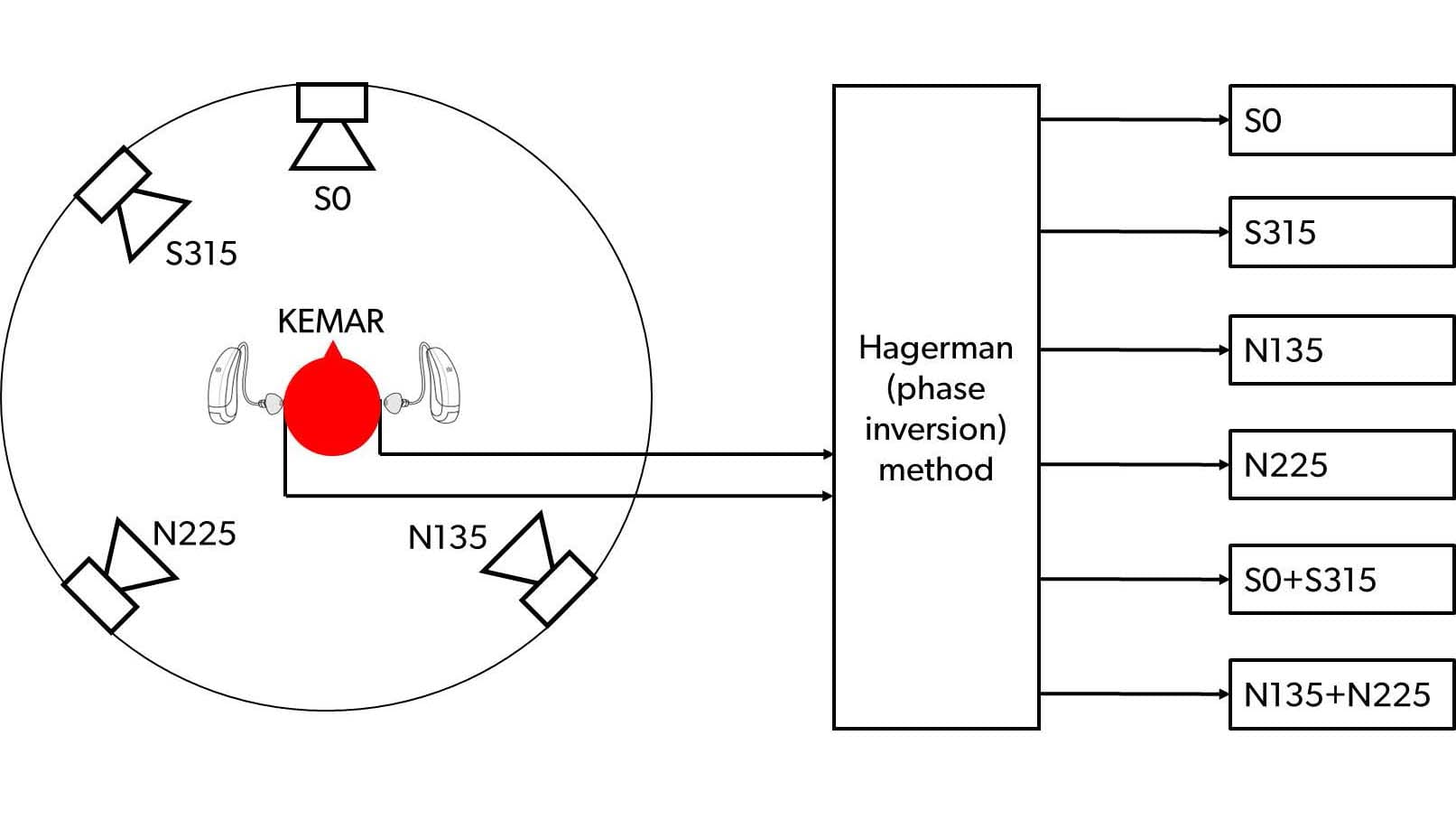
Figure 2. Setup used for output SNR measurements. Speech (S) signals were presented from the two loudspeakers in the front hemisphere, and noise (N) signals were presented from the two loudspeakers in the back hemisphere. The signals processed by the hearing aids were recorded in the KEMAR ears, with and without phase inversion of each signal, and the Hagerman method was used to generate estimates of the various S and N signals, both alone and in combination.
To determine the output SNR, the hearing aids were positioned in the KEMAR ears, and a series of recordings were made with and without phase inversion of the different input signals. Applying the phase-inversion technique on the recordings then allowed estimation of each of the processed signals at the output of the hearing aids, both for the individual speech and noise sources, and for the combined speech and noise, as illustrated in Figure 2.
In the measurements, the sound signals from the four loudspeakers were presented as shown in Figure 3. The figure shows how signals from all four loudspeakers were presented for 50 seconds before the actual recordings were started. This 50-second time lag, as mentioned above, ensures all noise reduction features are activated and stable before the phase-inversion technique is applied. The time required to settle varied across the hearing aids, and the value of 50 seconds was determined by the fact that one of the hearing aids required just above 40 seconds to reach a stable condition in this setup. At t=50 seconds the recording was started, and the presentation scheme changed to simulate a group conversation with two talkers taking turns speaking. This was established by alternating between S0 and S315, with each signal being presented for 10 seconds as indicated in Figure 3. Each recording included two sections with S0 and two sections with S315, for a total of 40 seconds.
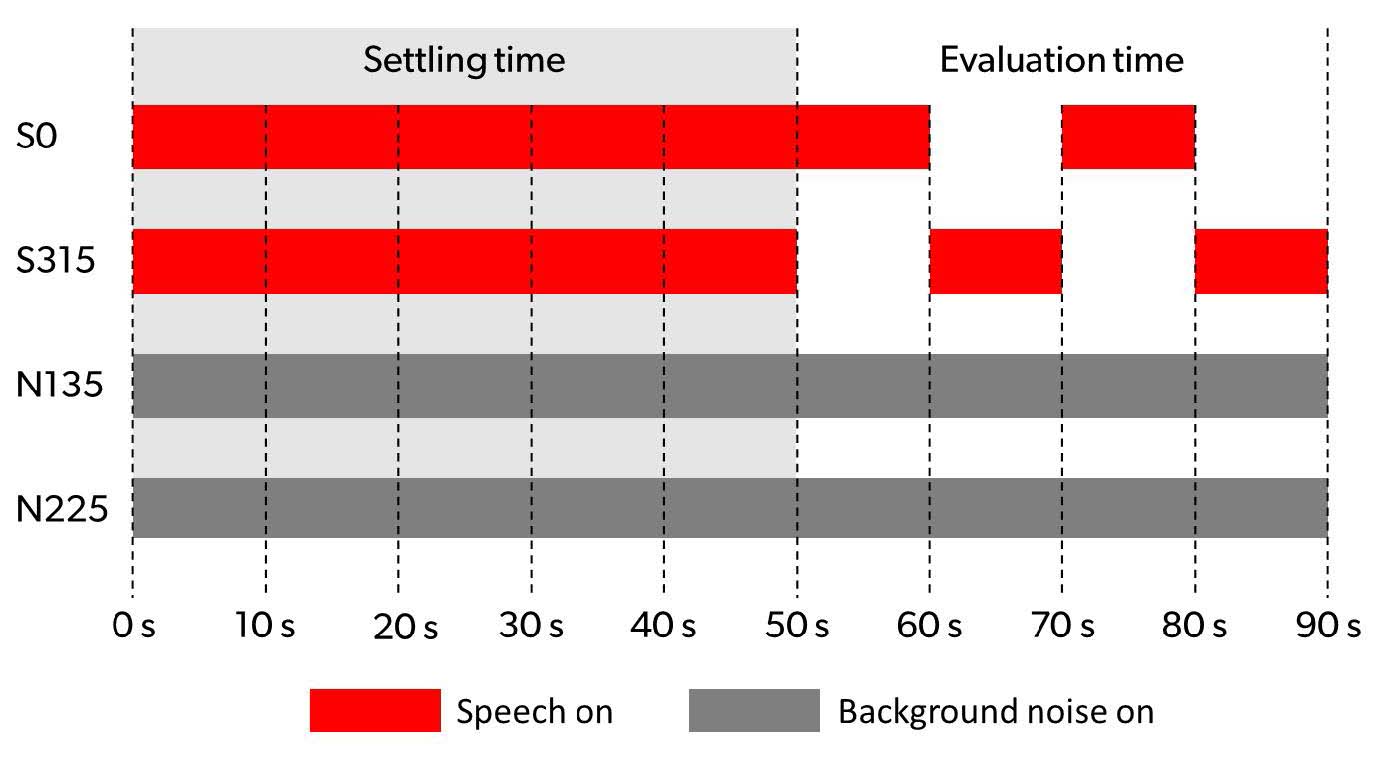
Figure 3. Presentation of input signals from the four loudspeakers. The signal presentation started at t=0, while recordings used for the analysis were started at t=50 seconds to allow enough time for the hearing aids to reach a stable working condition (i.e., the same condition for each hearing aid in each recording). The analysis was based on 40 seconds of recordings (evaluation time), including two sections of 10 seconds from each of the two talker locations (S0 and S315). This setup simulates the turn-taking of two talkers in the frontal hemisphere of the wearer with continuous noise originating from the rear/lateral hemisphere.
The outcome of the analysis is the output SNR of the different hearing aids, averaged across the evaluation time. Due to the test layout where speech was presented from the front and from the left side of the KEMAR, we present the output SNRs of the left hearing aid, which is most relevant to speech understanding due to the better ear effect. In the analysis, we calculated the overall conversation SNR, (S0+S315)/(N135+N225), based on the entire 40 seconds recording.
Furthermore, we calculated the output SNR for each of the two talker locations (front and lateral), that is, S0/(N135+N225) and S315/(N135+N225), respectively. For these two latter analyses, to avoid possible analysis ambiguities created close to the transitions between talkers, only 6 seconds of each speech period was included in the analysis, disregarding the 2 seconds at the start and the 2 seconds at the end of each 10-second period.
Hearing aids
In this investigation, the performance of Signia Pure Charge&Go IX was compared to the performance of premium receiver-in-canal (RIC) hearing aids of four competitors. The competitor devices are labeled Brand A-D. At the time of the investigation, each hearing aid represented the most current premium RIC device offered by each respective competitor.
For the measurements, Signia IX and all four competitor hearing aids were programmed to a symmetrical, flat 50 dB hearing loss, using the default setting prescribed by each manufacturer’s recommended (proprietary) fitting rationale. To ensure valid application of the phase-inversion technique, features manipulating the signal phase (feedback cancellation and frequency compression) were deactivated in all the hearing aids. The hearing aids were fitted to the KEMAR’s ears using closed coupling eartips.
The recordings were also made with the open (unaided) KEMAR ears. This allowed the open ear SNR to be calculated and used as a reference, representing the input SNR.
Results
The overall conversation output SNR, measured across the two talker positions, is plotted in Figure 4 for Signia IX, the four competitor devices, and the unaided KEMAR. The figure shows that all but one of the hearing aids provided a higher output SNR than the reference (input) SNR measured in the open ear of the KEMAR. Thus, these four hearing aids provided an SNR benefit in this conversation scenario. The exception was Brand C, which provided an SNR around 5 dB lower (worse) than the open ear SNR in this test setup. While this measurement cannot be used to generalize the speech-in-noise performance of Brand C in other setups, this result indicates that in this particular conversation scenario, wearers do not yield an SNR benefit with Brand C’s device.
Among the four hearing aids offering a benefit compared to the unaided KEMAR, Signia IX clearly offered the largest benefit. The overall output SNR of Signia IX was 11.8 dB, while the best competitor device (Brand B) offered an output SNR of 7.7 dB. That is, in this conversation scenario, Signia IX offered an improvement in output SNR of 4.1 dB compared to the nearest competitor. Compared to the open KEMAR ear, Signia IX improved the overall conversation SNR by almost 8 dB.
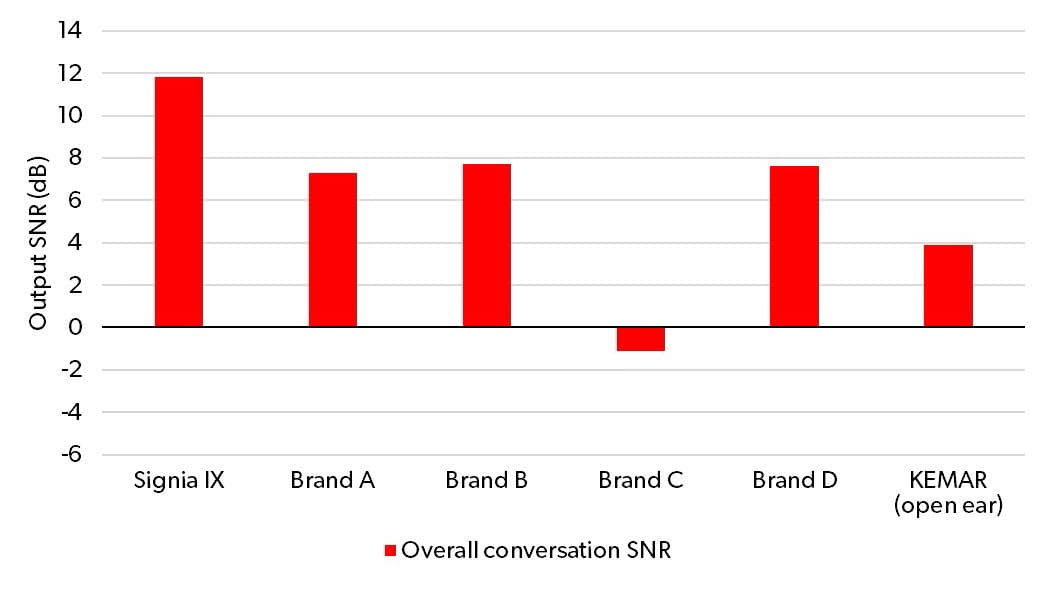
Figure 4. Overall conversation output SNR across the two talker locations, for Signia IX and the four competitor devices (Brand A-D), and for the unaided (open ear) KEMAR.
The output SNR was also calculated for each of the two talker locations. The results are plotted in Figure 5, with gray bars showing the output SNR values for the frontal talker, and black bars showing the output SNR values for the lateral talker. In general, for all the hearing aids, the difference between frontal and lateral SNRs reflect the natural difference between frontal and lateral SNR, which was observed for the open ear KEMAR. This difference (of almost 5 dB) was caused by the interaction between the directional characteristics of the outer ear and torso of the KEMAR, the acoustics of the measurement room, and the actual positions of the speech and noise sources in the test setup.
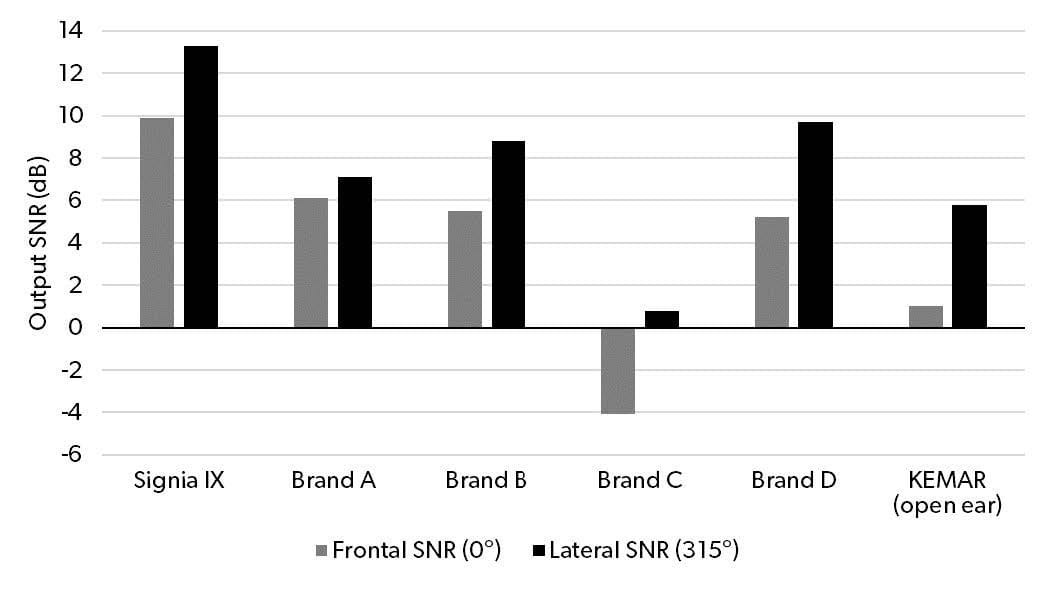
Figure 5. Output SNRs for the frontal and lateral talker locations, respectively, for Signia IX and the four competitor devices (Brand A-D), and for the unaided (open ear) KEMAR.
Regarding the differences between the hearing aids, even though some changes in the ranking of the hearing aids appear when looking at the frontal and lateral SNRs, respectively, the overall trends in Figure 5 generally follow the trend in the overall conversation SNR shown in Figure 4 For example, it is clear that Brand C had problems for both talker directions, which show SNR values around 5 dB poorer than the open ear KEMAR values.
Importantly, for both the frontal and lateral output SNRs, Figure 5 shows a very clear Signia IX advantage compared to the competitor devices. For Signia IX, an output SNR of 9.9 dB was measured for the frontal talker, which was 3.8 dB higher than the best competitor (Brand A), and 8.9 dB higher than the open-ear SNR. For the lateral talker, Signia IX offered an output SNR of 13.3 dB, which was 3.6 dB higher than the best competitor (Brand D) and 7.5 dB higher than the open-ear SNR. These findings suggest that Signia IX and RTCE offers a substantial benefit when listening to all the participants in a conversation, independent of their position relative to the wearer.
Discussion
In this study, we investigated the output SNR performance of Signia IX and four competitor devices in a simulated group conversation scenario with two conversation partners in the front hemisphere and with continuous noise coming from the back hemisphere. The results showed Signia IX outperformed all four competitors, offering an overall conversation SNR benefit of 4.1 dB (compared to the nearest competitor) and benefits of at least 3.6 dB for specific talker directions.
We believe that this pronounced difference between Signia IX and the premium devices of four competitors stems from the RTCE processing. One unique element of RTCE is the advanced analysis of the conversation layout, which continuously pinpoints conversation partners as well as the location of noise sources. In the given measurement setup, the system always knows whether speech is coming from the front or the side direction. This allows another unique element of RTCE, the multi-stream architecture with its three focus streams (which are added to the focus stream of the split processing), to tailor the processing of each stream according to the conversation layout, thereby creating a live auditory space where active talkers are enhanced, and other surrounding extraneous sounds are processed independently. By updating the system 1,000 times per second, RTCE adapts to any changes in the conversation layout, including the turn-taking between participants in the conversation. The test setup in our investigation simulated this turn-taking by presenting speech alternating from the front and the side of the KEMAR manikin.
The SNR benefits measured for both frontal and lateral talker directions – attributed to the unique properties of RTCE – enable the wearer to not always have to face the active talker during the conversation. Not always having to face the talker facilitates more natural behavior where the wearer can turn their head and look in the direction they want without missing what is being said from other directions.
The fast adaptation to the transitions between talkers, allowed by RTCE’s multi-stream architecture, is probably one of the main reasons for the measured SNR benefits provided by Signia IX. A commonly used approach in more traditional hearing aid processing is single-stream processing where speech and noise are processed in the same way. Even though adaptive processing may be applied in a way where the single-stream system actually changes processing behavior when two conversation partners take turns talking, it will often happen so slowly that it cannot adapt to fast changes like the ones used in this test – even though conversations where each talker speaks for 10 seconds before another talker takes over are commonly experienced by most people.
It is well-established that there is a direct connection between SNR and speech understanding ability. Consequently, improving the output SNR of a hearing aid – in a conversation or any other challenging situation where a hearing aid wearer listens to speech in background noise – will increase the wearer’s speech understanding ability. However, this connection is not linear and depends on the absolute SNR of the listening situation. For example, improving the SNR from -24 dB to -20 dB will typically not make a difference, since it’s virtually impossible to understand the speech in these highly adverse listening conditions. Likewise, improving the SNR from 20 dB to 24 dB will not, for most hearing aid wearers, make a difference because they already can understand everything with little effort in such favorable SNRs.
In this study, we assessed the output SNR under very well-defined yet quite realistic test conditions to allow a meaningful comparison of the SNR performance offered by the different hearing aids. The selected input SNR of around 4 dB was just below the 4.6 dB reported by Smeds et al. (2015) as the median SNR for speech in babble in realistic sound scenarios.
The effect of improving the hearing aid’s output SNR is most important in listening situations where wearers begin to struggle to understand speech. This often occurs at slightly positive SNRs, like the 4 dB used in the present benchtop investigation. These SNRs are often close to the steepest part of the underlying performance-intensity (P-I) function (psychometric function). This is illustrated in Figure 6, which shows an ideal P-I function where speech intelligibility (in percent) is plotted as function of the SNR. The figure illustrates, as mentioned above, how changes in the SNR at very low or very high SNRs will have limited effect on the speech intelligibility, whereas even modest SNR changes around the steep part of the function can have a substantial effect on speech intelligibility.
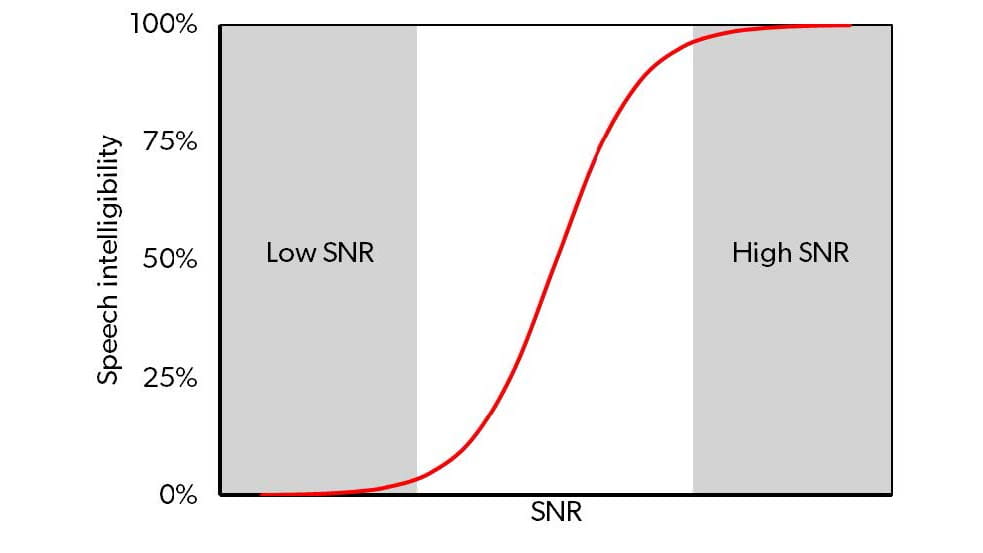
Figure 6. Example of an ideal psychometric performance-intensity (P-I) function, showing the relationship between signal-to-noise ratio (SNR) and speech intelligibility.
The P-I function is highly individualized, and it will depend mainly on the hearing loss as well as the type of speech and noise of the listening situation. However, in general, the steepest slope will often be in the range 10-15 percent/dB (or even higher under certain conditions). Thus, if being close to the SNR associated with the steepest part of the P-I function, a change in the hearing aid’s output SNR of 4 dB can, in theory, provide a change in speech understanding of 40%-60%. This may be the difference between not being able to follow a conversation (and perhaps give up) and being able to understand virtually everything. It may be the difference between having to spend a lot of mental effort to follow a conversation and having an effortless and pleasant conversation experience. Or it may be the difference between being excluded from a conversation and being able to fully engage and contribute to it.
More research studies will be carried out to further investigate the perceptual benefits offered by RTCE and how it impacts the Signia IX wearers’ ability to perform and contribute when being in group conversation situations.
Summary
In this paper, we have presented the results of a study on the SNR performance provided by Signia Integrated Xperience and four competitor hearing aids. A technical assessment was performed in an acoustic setup simulating a group conversation scenario in background noise with two conversation partners located in front of and to the side of the hearing aid wearer. The assessment was based on the Hagerman phase-inversion technique, allowing estimation of the output (processed) SNR provided by the hearing aids in the given setup.
Our benchtop analysis demonstrates a clear SNR performance advantage for Signia Integrated Xperience with RealTime Conversation Enhancement when compared to the processing approaches used by four competitors. Compared to the best of the four competitor devices, the improvement in overall conversation SNR from Signia IX was 4.1 dB. The talker-specific SNRs calculated for the two different talker locations also showed a clear Signia IX advantage for both the frontal and lateral SNR, with observed benefits of 3.8 dB and 3.6 dB, respectively, compared to the best competitor devices. Offering a benefit both for talkers in the front and talkers to the side allows Signia IX wearers a more natural behavior where they can turn their head as they want without having to face the active talker all the time.
Since improvements in the output SNR can be linked directly to improvements in speech understanding if the wearer is situated in a noisy group conversation situation where they struggle to participate, the results of this study suggest that Signia IX offers a potential benefit in such situations, making it easier for the wearer to participate in and contribute to the conversation.
References
Aubreville M. & Petrausch S. 2015. Directionality assessment of adaptive binaural beamforming with noise suppression in hearing aids. 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP): IEEE, pp. 211-215.
Branda E. 2021. Split-processing: A new technology for a new generation of hearing aid. Audiology Practices, 13(4), 36-41.
Hagerman B. & Olofsson Å. 2004. A method to measure the effect of noise reduction algorithms using simultaneous speech and noise. Acta Acustica United with Acustica, 90(2), 356-361.
Holube I., Fredelake S., Vlaming M. & Kollmeier B. 2010. Development and analysis of an international speech test signal (ISTS). International Journal of Audiology, 49(12), 891-903.
Jensen N.S., Samra B., Kamkar Parsi H., Bilert S. & Taylor B. 2023. Power the conversation with Signia Integrated Xperience and RealTime Conversation Enhancement. Signia White Paper.
Smeds K., Wolters F. & Rung M. 2015. Estimation of signal-to-noise ratios in realistic sound scenarios. Journal of the American Academy of Audiology, 26(2), 183-196.