
Signia Xperience Super Power devices
- the true heroes
The white paper discuss important aspects of fitting hearing aids to people with severe to profound hearing loss in general, and specifically highlights the new features in Signia Motion C&G SP X supporting and innovating this field, also supported by study results.
Created Updated
Written by Maja Serman, Ulrich Giese, Niels Søgaard Jensen & Erik Harry HøydalIn a recent investigation of the prevalence of hearing loss in the United States, Goman and Lin (2016) estimated that 2.1 million (0.8%) Americans aged 12 years or older have a bilateral severe to profound hearing loss, defined as the 4-frequency pure-tone-average threshold of the better ear being above 60 dB HL. This number of people may seem relatively small in comparison to the prevalence of hearing loss per se, which, in the same analysis, was estimated to be 38.2 million (14.3%) Americans with a bilateral hearing loss. However, the relatively small percentage says nothing about the challenge and importance of successfully compensating this type of hearing loss: fitting severe to profound hearing losses is considered to be one of the most difficult tasks in the hearing care profession, and, at the same time, a successful fitting is of the highest importance for those affected.
In this whitepaper, we discuss the underlying reasons that make severe and profound hearing losses so hard to fit with hearing instruments, before describing how the Signia Xperience fitting strategy (XFit) for these hearing losses addresses the fitting challenges, in terms of gain and compression. We then outline the exciting new features in the Xperience Charge & Go Super Power hearing aids and the studies that show both real-life preference and better speech intelligibility for people with severe and profound hearing losses.
The challenge of fitting a severe to profound hearing loss
Severe to profound hearing loss is a commonly used classification, although it has been defined using different audiometric thresholds (e.g. Keidser et al., 2007; Margolis and Saly, 2007). Keidser et al. (2007) define an audiometric pure tone average (PTA) for the better ear (at 0.5, 1 and 2 kHz) between 60 and 90 dB HL as an indication of a severe loss and a PTA above 90 dB HL as an indication of a profound loss. However, PTA values on their own cannot convey the reduction in ability to understand speech in difficult listening situations for this group of hearing losses. From a physiological point of view, it is safe to assume that with this type of hearing loss both outer hair cells (OHC) and at least some if not a substantial part of the inner hair cells (IHC) are severely damaged, resulting in both loss of audibility and loss of frequency selectivity.
The difference between these two dimensions of hearing loss and their impact on the demands on hearing instrument processing is outlined in Figure 1. It is a simplified representation of the displacement of the basilar membrane due to two travelling waves, encoding two tones close in frequency. Assuming critical bandwidth separation, the top panel shows that in the healthy cochlea there is sufficient displacement of the basilar membrane to resolve the two tones, enabling the listener to perceive them as separate sounds. The middle panel depicts the consequences of OHC loss for the same stimuli – smaller and rounder tone peaks which may result in loss of frequency selectivity and spectral smearing. The bottom panel shows that the hearing instrument can increase the amplitude of the displacement, but this does not restore the sharpness of the peaks and therefore cannot restore the original frequency selectivity of the healthy cochlea.
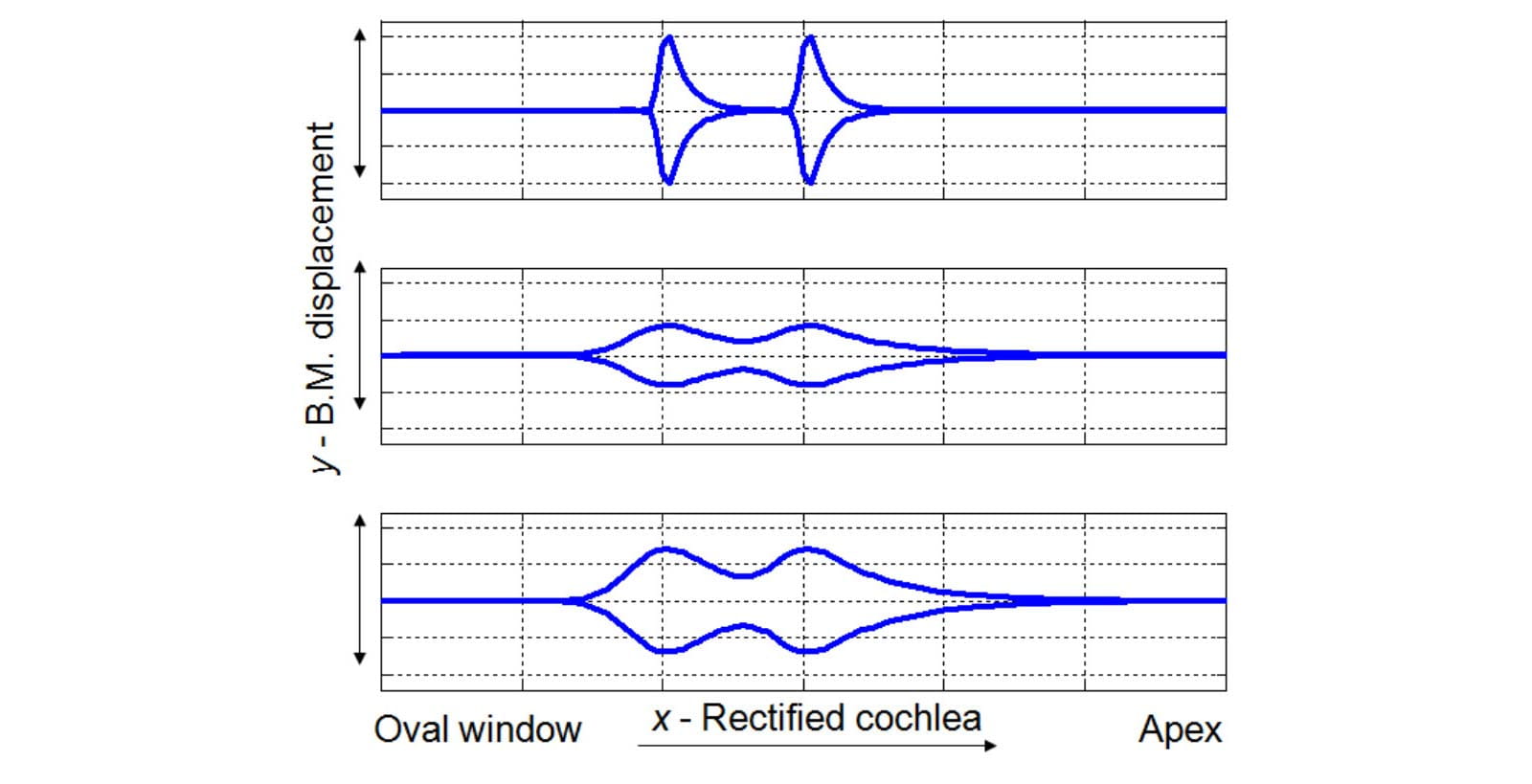
Figure 1. A schematic representation of the impact of the OHC loss on cochlear processing. Top panel: envelope of the basilar membrane displacement in the healthy cochlea due to stimulation by two tones close in frequency. Middle panel: the consequence of the OHC loss: reduction in amplitude and smeared out peaks. Bottom panel: the same input signals amplified through the hearing instrument: the displacement amplitude is restored but the peaks are still rounded (adapted from Kemp, 2002; Venema, 2003; Moore, 2007).
As one moves beyond a hearing loss of 60 dB HL, the IHC loss becomes more prominent which may for the parts of the cochlea with very few or no IHC left, render the amplification strategy as ineffective. It is this combination of the OHC and IHC loss in people with severe to profound hearing loss that makes compensating their hearing loss with hearing instruments so challenging.
Speech understanding in quiet and in noise
The perceptual effects of cochlear frequency resolution can be observed in normal hearing listeners, through the phenomenon known as the upward spread of masking. This effect occurs when a lower frequency signal, containing more energy, is masking higher frequencies, thereby “hiding” information that may be important for speech intelligibility (Egan and Hake, 1950).
The auditory filter width typically increases with increasing sensorineural hearing loss (Glasberg and Moore, 1985) which reduces frequency selectivity and thus results in an even more prominent effect of upward spread of masking in terms of masked thresholds (Klein et al., 1990). For example, the more intense lower-frequency components of the speech signal mask the weaker high-frequency speech components, resulting in decreased speech intelligibility (Klein et al., 1990; Stelmachowicz et al., 1985). In quiet, the availability of different, often redundant speech cues distributed across the speech spectrum may still provide some speech understanding even for people with severe hearing loss. In noisy situations, however, the loss of frequency selectivity due to the hearing loss has a much stronger impact on speech understanding because it reduces the ability to distinguish between spectrally important speech information and background noise. For example, the presence of noise between the spectra of two speech cues (such as the first and second vowel formants) requires finer selectivity to identify the two speech cues (Assmann and Summerfield, 2004). Numerous studies indicate that listeners with hearing loss show poorer speech perception in noise than normal hearing listeners and that the loss of frequency selectivity in individuals with hearing loss is very likely one of the causes (Stelmachowicz et al., 1985; Peters et al., 1998; Assmann and Summerfield, 2004; Athalye, 2010).
Sound distortion
People with severe to profound hearing loss also experience an increase in sound distortions. Let us look at the example of the perception of roughness (also described as dissonance and/or harshness) due to amplitude fluctuations known as beats. Beats occur when two tones that are close in frequency fall into a single auditory channel and appear united on the basilar membrane. As mentioned above, for people with a profound hearing loss, the reduction of OHC typically results in a broadening of the auditory filters, which may result in interaction between more widely spaced tones and in smearing of spectral details. Additionally, the tuning of the auditory filters becomes broader with increasing levels (Moore, 2003). The considerable hearing instrument gain required by this type of hearing loss may, therefore, also contribute to these perceived distortions.
In short, due to the loss of frequency selectivity, the loss of loudness, the loss of cochlear compression, the presence of dead regions and possibly other higher processing level factors, people with severe to profound hearing loss are very likely to experience an increase of unpleasant and dissonant sounds as well as lose the ability to separate competing sounds (e.g. speech from background noise). In some instances, the severe to profound sensory hearing loss is combined with a conductive component, which further increases the need for loudness compensation.
Designing hearing instruments that can sufficiently compensate for hearing losses in the severe to profound range thus presents a real challenge. On the one hand, in order to compensate for a dramatic loss of audibility, a truly powerful instrument is needed; on the other hand, reduced dynamic range and increased sensitivity to distortion and noise demand that this power is used wisely through appropriate fitting strategies and hearing instrument processing.
Motion C&G SP: The fitting strategy
A fitting strategy represents the essence of audiological knowledge and experience: it aims to compensate for a hearing loss while considering the constraints imposed by the hearing instrument (stability, coupling, receiver strength etc.). The latter is especially taken into account in proprietary fitting strategies, such as the new Xperience fitting algorithm (XFit). A fitting strategy comprises two aspects:
- The gain applied to the input signal: amplification as a function of frequency.
- The compression applied to the input signal: amplification as a function of input signal level, defined through compression knee points (CK), compression ratios (CR) and the temporal behavior of the compression system – conventionally described by the attack and release time constants.
The gain
Anecdotal and research evidence points towards different gain preferences in new and experienced hearing instrument wearers (Keidser et al., 2008). The nature of severe to profound hearing loss is such that new wearers are rare: this type of hearing loss is either congenital or it develops over time, so these are usually experienced hearing instrument wearers. However, their individual need for gain differs according to the severity, and to some extent, the etiology of the hearing loss.
Severe hearing loss may still allow for gain compensation across a relatively large frequency range, thereby increasing the chance of preserving speech understanding through gain compensation. Taking into account the effects of upward spread of masking, XFit for severe hearing losses enhances gain in the middle and high frequency range (see Figure 2).
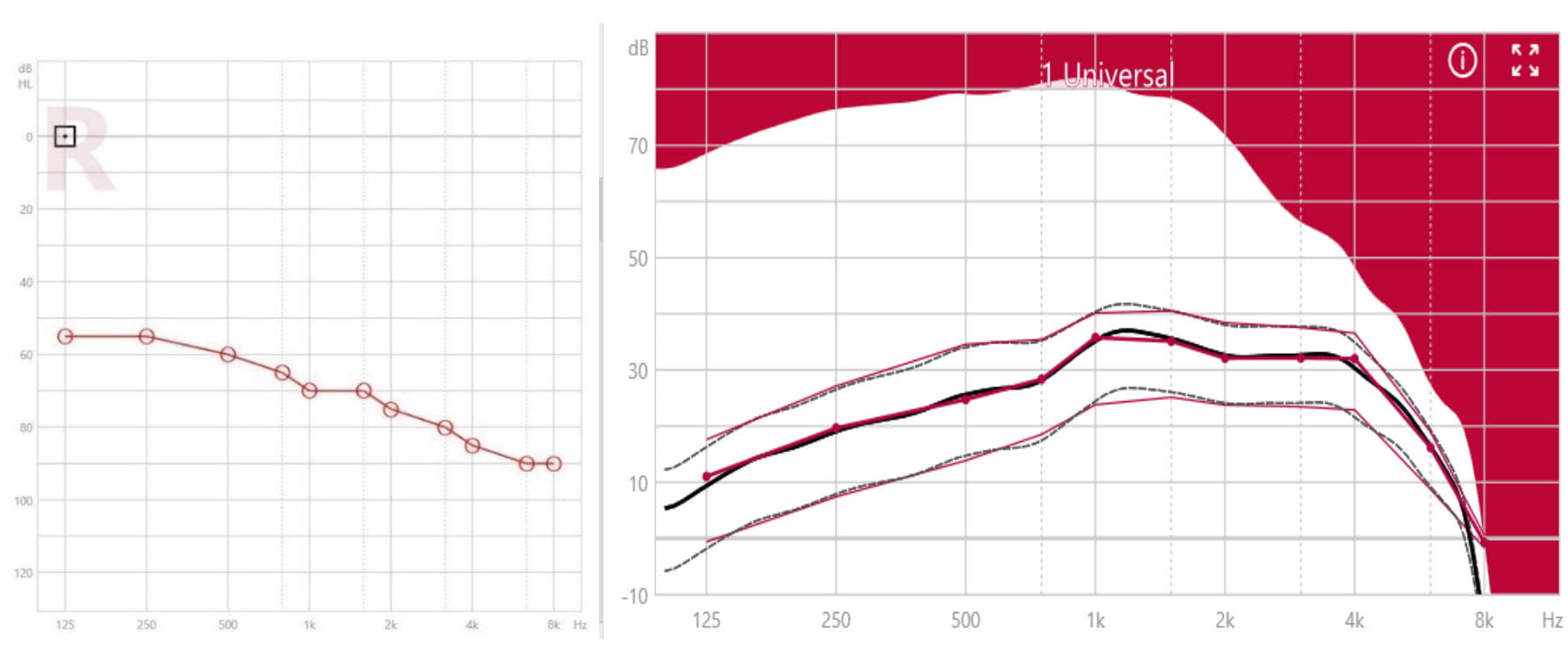
Figure 2. Example of a severe hearing loss (left panel) and the corresponding compressive XFit for Motion C&G SP in the insertion gain view (right panel). Target gain curves for different input levels are in red, hearing instrument simulated gain curves are dotted and black. The full-on gain curve shows the maximum insertion gain for 50 dB input level, for given measurement conditions.
For profound hearing losses, the residual hearing which can benefit from amplification is expected mostly in the low frequencies. An increased probability of not improving – and even decreasing – speech intelligibility by providing gain in high-frequency regions may occur due to cochlear dead regions (Moore and Malicka, 2013). For these reasons, XFit for profound hearing losses puts emphasis on more broadband gain in low frequencies (see Figure 3). These two different fitting approaches are automatically incorporated in XFit, as a function of the audiogram test frequencies, to facilitate the fitting for the hearing care professional while providing the optimum gain for the wearer.
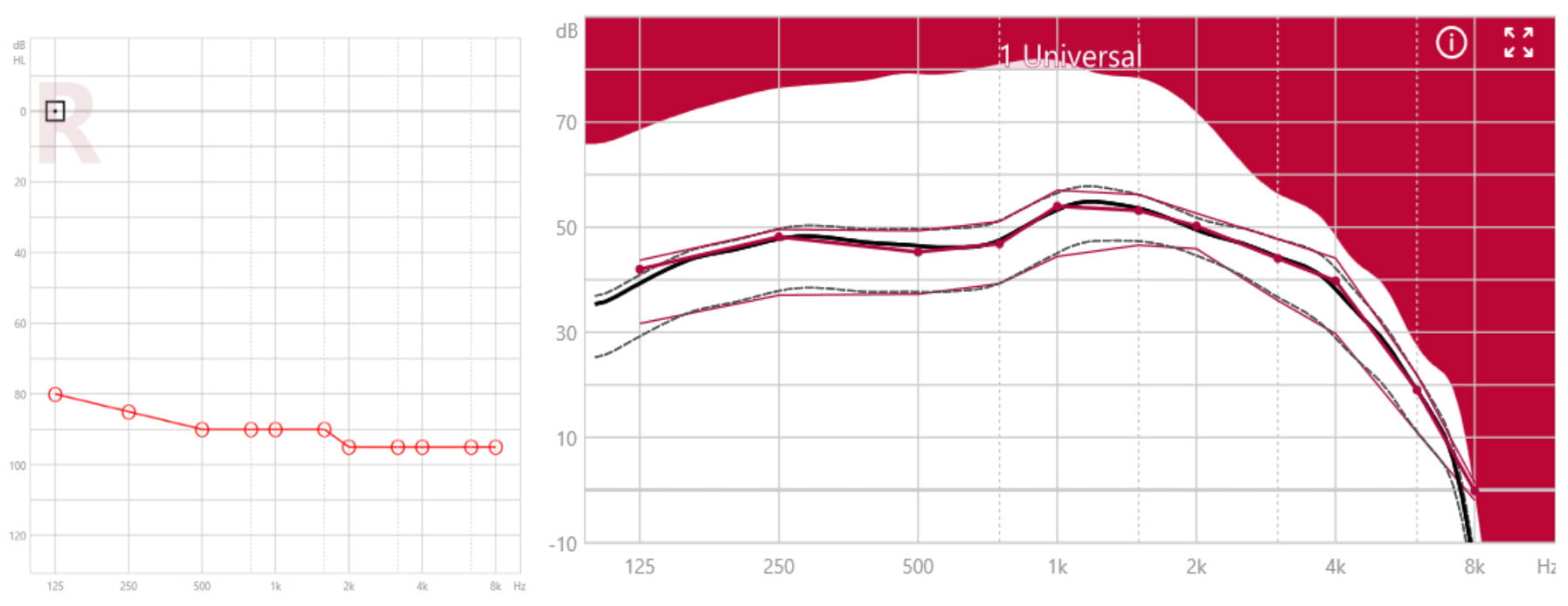
Figure 3. Example of a profound hearing loss (left panel) and the corresponding compressive XFit for Motion C&G SP in the insertion gain view (right panel).
The compression
Although they are generally experienced wearers, people with severe to profound hearing loss differ widely in their hearing instrument usage history: some have been fitted with linear hearing instruments since early childhood, while others started wearing hearing instruments with wide dynamic range compression (WDRC). The WDRC strategy is recommended for severe and profound hearing losses by Turton et al. (2020) with a recommendation to use only compression ratios lower than 3, which XFit follows. Because of their degree of hearing loss, most are full-time hearing instrument wearers who depend heavily on their instruments. With time, they are therefore likely to become highly acclimatized to specific amplification characteristics of their instruments. Although there is evidence that people can, with time and patience, acclimatize to a different compression strategy (Convery and Keidser, 2011), they may at first be reluctant to do so. For this reason, XFit gives the hearing care professional the choice between two compression strategies for Motion C&G SP (see Figure 4).
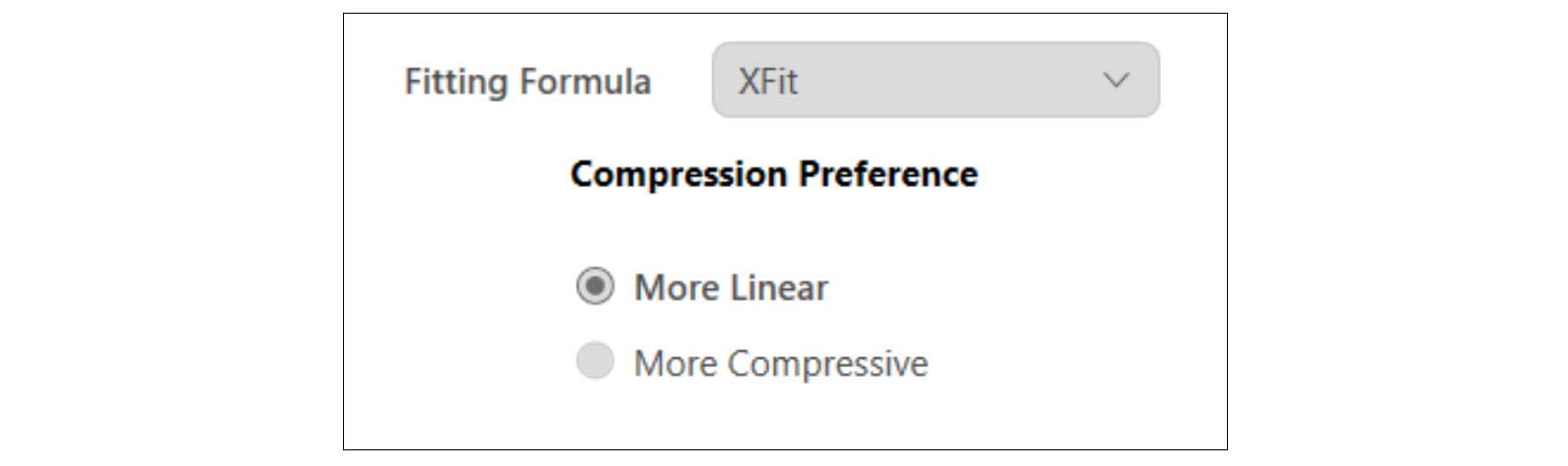
Figure 4. Compression strategies for XFit.
For those who are already used to WDRC, XFit offers the “More Compressive” amplification strategy. This compression strategy allows for compression ratios of up to 3:1 for the whole input range above the first CK which is pre-set at 50dB SPL, thus enabling an effective compensation for people’s reduced dynamic range. The compression effect for a static input signal can be seen in the right panels of Figure 2 and Figure 3 by the pronounced differences between the target gain curves for different input levels (50, 65 and 80 dB SPL, respectively). The “More Compressive” strategy is the recommended fitting approach since it enables the full use of the residual dynamic range while still keeping the peaks of the signal below the person’s uncomfortably loud region. It is also more effective in preserving both sound quality and speech intelligibility through the advanced compression system offered with Signia Xperience instruments (see below). The “More Compressive” strategy, therefore, is the default fitting approach in the fitting software.
For those who are used to and prefer linear amplification, we offer the “More Linear” strategy: this provides linear amplification up to the second CK set at 65 dB SPL. After the second CK, only mild compression is provided, which never goes higher than a compression ratio of 2.5. The effects of “More Linear” compression are shown in Figure 5 (for the same audiograms shown in left panels of Figure 2 and Figure 3). Here, the reduced compression is seen in the much smaller differences between the target gain curves for different input levels, especially between the 50- and 65-dB SPL input level target curves, compared to the “More Compressive” strategy used for of Figure 2 and Figure 3. While it may seem counter-intuitive to offer linear amplification for such a small residual dynamic range, experience tells us that there are people within this hearing loss group who are used to and prefer the hearing instrument changing the dynamics as little as possible, even if this means that softer sounds will often be inaudible and higher level inputs may be limited.
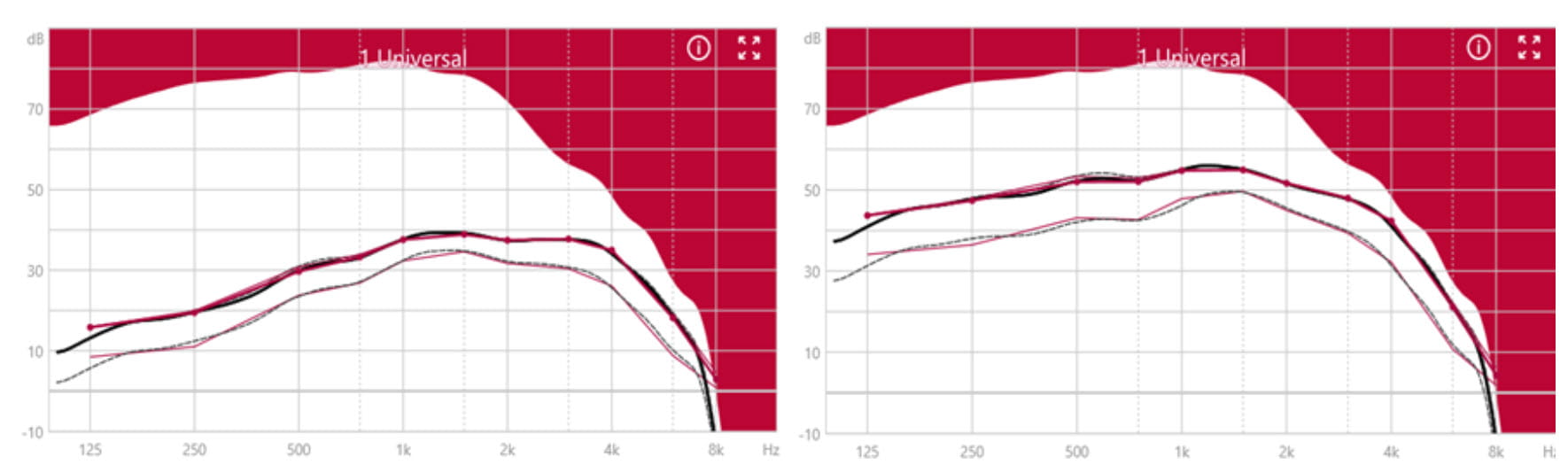
Figure 5. The “More Linear” fit for Motion C&G SP. Left panel: for the severe hearing loss shown in Figure 2. Right panel: for the profound hearing loss shown in Figure 3. Observe that unlike the simulation curves shown in the right panels of Figure 2 and Figure 3, where a clear separation between the gain for soft and average input levels is visible, this fitting strategy prescribes the same gain for soft and average inputs.
Dynamic range and compression
As mentioned in the previous section, it is important to select an appropriate amplitude compression strategy for people with severe to profound hearing loss: in some cases, this involves using strong compression for soft, moderate and high input levels, while in other cases, using weaker compression is appropriate. In addition, the time constants of the compression algorithm are also very important for this group: due to the broadening of the auditory filters and consequent loss of frequency selectivity, some may have learned to rely more on the temporal cues of the speech signal (Turner et al., 1995; Kishon-Rabin et al., 2009; Souza et al. 2015).
In order to preserve both spectral cues and the temporal envelope of speech, speech input would ideally require low compression ratios and slow compression time constants. On the other hand, in order to stay below the uncomfortable sound levels for natural, dynamically fluctuating sounds, higher compression ratios and faster compression time constants are required. Theoretically then, given the limitations of their dynamic range, people with severe to profound hearing loss would require high compression ratios and short time constants. In practice, it has been shown that such compression settings most often result in a degradation of speech intelligibility, sound quality and consequent dissatisfaction with the hearing instrument (Gatehouse et al., 2006; Keidser et al., 2007; Souza et al., 2012). Basically, one needs an “intelligent compressor” which is capable of adapting compression according to the properties of the signal.
This is why the XFit adaptive compression concept is extremely important for this group. For small level changes in the input signal it reacts slowly thereby preserving spectral and temporal speech cues as well as preserving the quality and naturalness of the sound. When more substantial input level changes are detected, the compression speeds up. The adaptive compression allows for a continuum of time constants as a function of level dynamics. In this way, large amounts of compression can be applied only when really needed, and the time constants can be adjusted according to the input signal. The result is a balance between speech intelligibility and sound quality while ensuring full audibility and safety for the hearing aid wearer. In this way, the XFit adaptive compression strives towards the same principle as the healthy auditory system: ensuring a freedom of listening in the natural sounding world without any discomfort.
New features
A new range of Connexx features allow for targeted, dedicated fittings for this group. Let us look at them in detail.
Individualized fitting through Dynamic Soundscape Processing
The new Dynamic Soundscape Processing (DSP) feature is a powerful tool that combines several features into one, enabling the HCP to set the right balance for each individual. In Connexx you will see the DSP-slider, going from Awareness to Highlight depending on how much support the individual needs and prefers. Many people with severe to profound hearing loss have used hearing aids most of their lives and are used to a more unprocessed sound. For those individuals, the slider could be placed towards Awareness. Moving the slider will impact a vast number of parameters. Most importantly, it will impact when directionality and noise suppression is activated and at which strength. For those who need or prefer more support, you can set the slider closer to Highlight. This will ensure that directionality and noise suppression are applied as soon as the SNR gets poor and the noise level increases. If you are uncertain about the preference of the wearer, you should place the slider at Balance and let the wearer find their best approach themselves, through the revolutionary AI-assistant found in the Signia App – the Signia Assistant.
Signia Assistant
Through the Signia Assistant, the wearer can adjust the slider to their preferred setting in their daily life (Høydal et.al., 2020). There is no visible slider in the app, but as the wearer gets assistance from the Signia Assistant, the slider will automatically be adapted in the background, of course visible to the HCP in Connexx. The Signia Assistant is designed with simplicity in focus (Figure 6). Interactions are done in a dialogue form and always in non-technical language. If the wearer is used to texting, they should be able to use the Signia Assistant.
If the wearer find themselves struggling to follow conversation or dissatisfied with the sound in general or with their own voice, they can simply indicate the problem to the Signia Assistant, which will change the setting on their device and then let them choose between the new or old sound. The Signia Assistant will learn the changes and preferences of the wearer and adapt over time to best suit each individual.
Because they hear everything through the hearing aids, with no direct sound, it is extremely important for wearers with severe and profound losses to be in control of how everything sounds, and it can be a challenge to find the right balance in the clinic. The Signia Assistant addresses this by letting them optimize the sound to their preference in their everyday life.
Every change done by the wearer can be viewed in Connexx when the wearer returns to the clinic, meaning the hearing care professional is always informed and on top of the settings of the device.
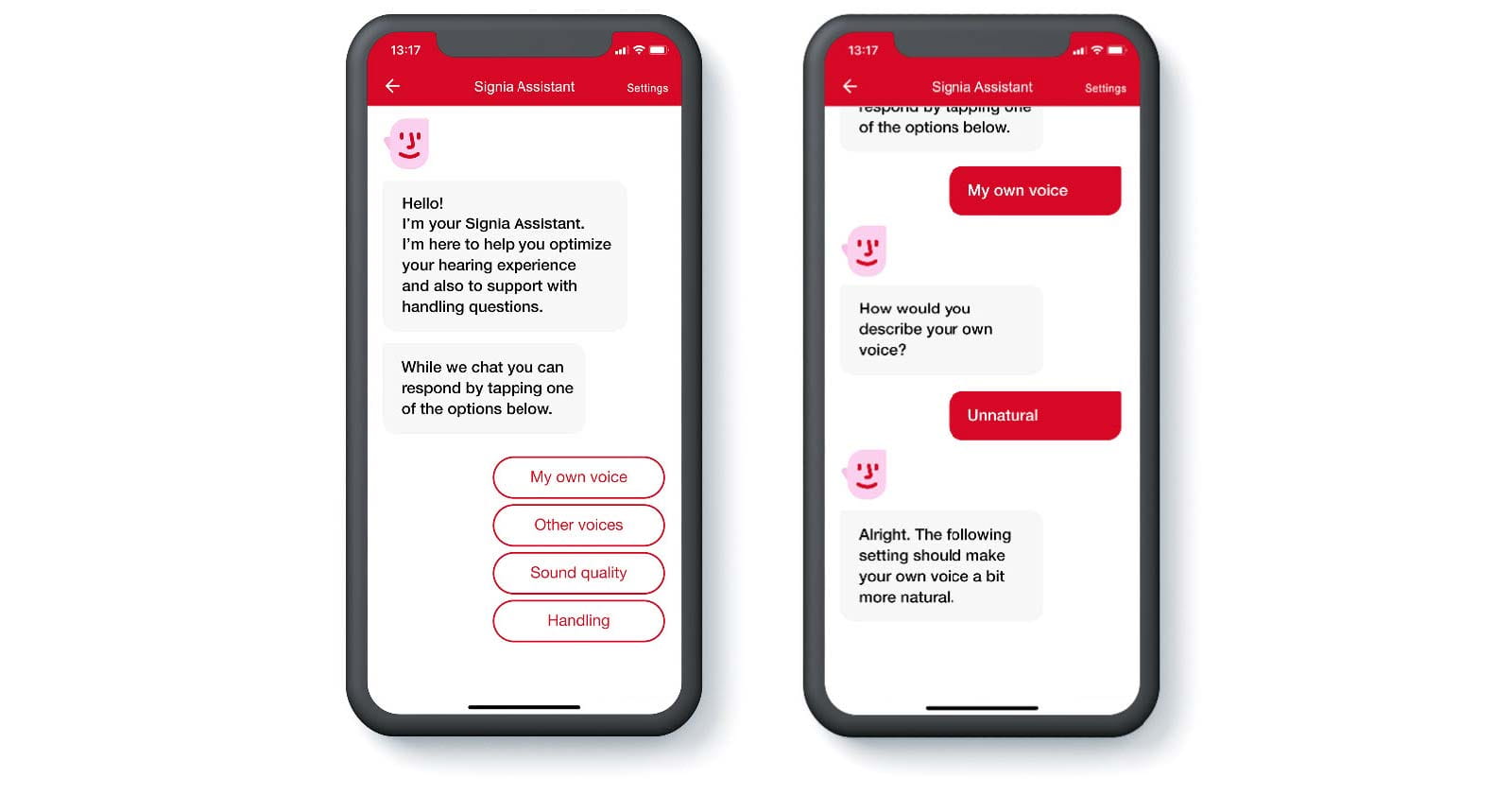
Figure 6. The Signia Assistant is an advanced tool with a simple interface where the wearer can optimize the sound to their liking.
Own Voice Processing
Even though many SP-wearers have gotten used to their own voice, it can be quite disturbing when applying the required amount of amplification. With the patented Signia innovation Own Voice Processing (OVP), the wearer does not have to choose between sufficient amplification and comfort of own voice, they can simply have both. The OVP feature recognizes when the wearer is speaking and immediately applies a different gain (Høydal, 2017; Powers et.al.,2018) For all external sounds, the gain remains as prescribed. This way, you do not have to find a compromise between the two, or deal with overamplification of own voice, a common problem for Super Power wearers.
Rechargeability
A big trend in all consumer goods, and now also in hearing aids, is people shifting from traditional single-use batteries over to a rechargeable solution. For the first time, wearers of Super Power (SP) devices can also enjoy the convenience of rechargeability in Motion C&G SP. This has not previously been available for this group, mainly due to high energy consumption and low-capacity batteries. With Signia Xperience, we introduce a fully rechargeable behind-the-ear portfolio, including SP-devices.
It’s extremely important for people with greater hearing losses, that the hearing aids do not run out of batteries or stop working. Therefore, we have focused on durability, energy efficiency and finding a battery cell with capacity beyond what has previously been possible in hearing aids. The result is a Super Power device that can last for up to 61 hours on one charge cycle, and 57 hours including 5 hours of streaming, making traditional batteries redundant and ensuring a more environmentally friendly solution also for this group of wearers.
Study results
The real-life performance of Motion C&G SP was assessed in a home trial where participants were fitted with the hearing aids in the prescribed setting and used them in everyday life. Due to limitations dictated by the coronavirus pandemic, it was only possible to include six participants with severe-profound hearing loss in the study. The mean age of the participants was 60.5 years, and the mean four-frequency pure tone average (PTA4) hearing threshold was 74.4 dB HL. At the end of the trial period, the participants filled in a questionnaire that included a direct comparison with their own hearing aids, which included four different brands for the group. In this comparison, the participants stated their preference between Motion C&G SP and their own hearing aids on speech intelligibility, sound quality and listening effort, as well as general preference. Figure 7 shows how many participants stated a given preference within each domain. It can be seen that a majority of Motion C&G SP preferences was observed within all domains, most substantially within speech intelligibility and listening effort, and that five out of the six participants had an overall preference for Motion C&G SP. It should be noticed that one participant preferred their own hearing aids in all domains. This participant would probably have benefitted from a more extensive fine-tuning to address the non-optimal loudness perception that was mentioned as a reason for the preference for own hearing aids. In the study, only adjustments of master gain were done before sending the participants home to try out the hearing aids.
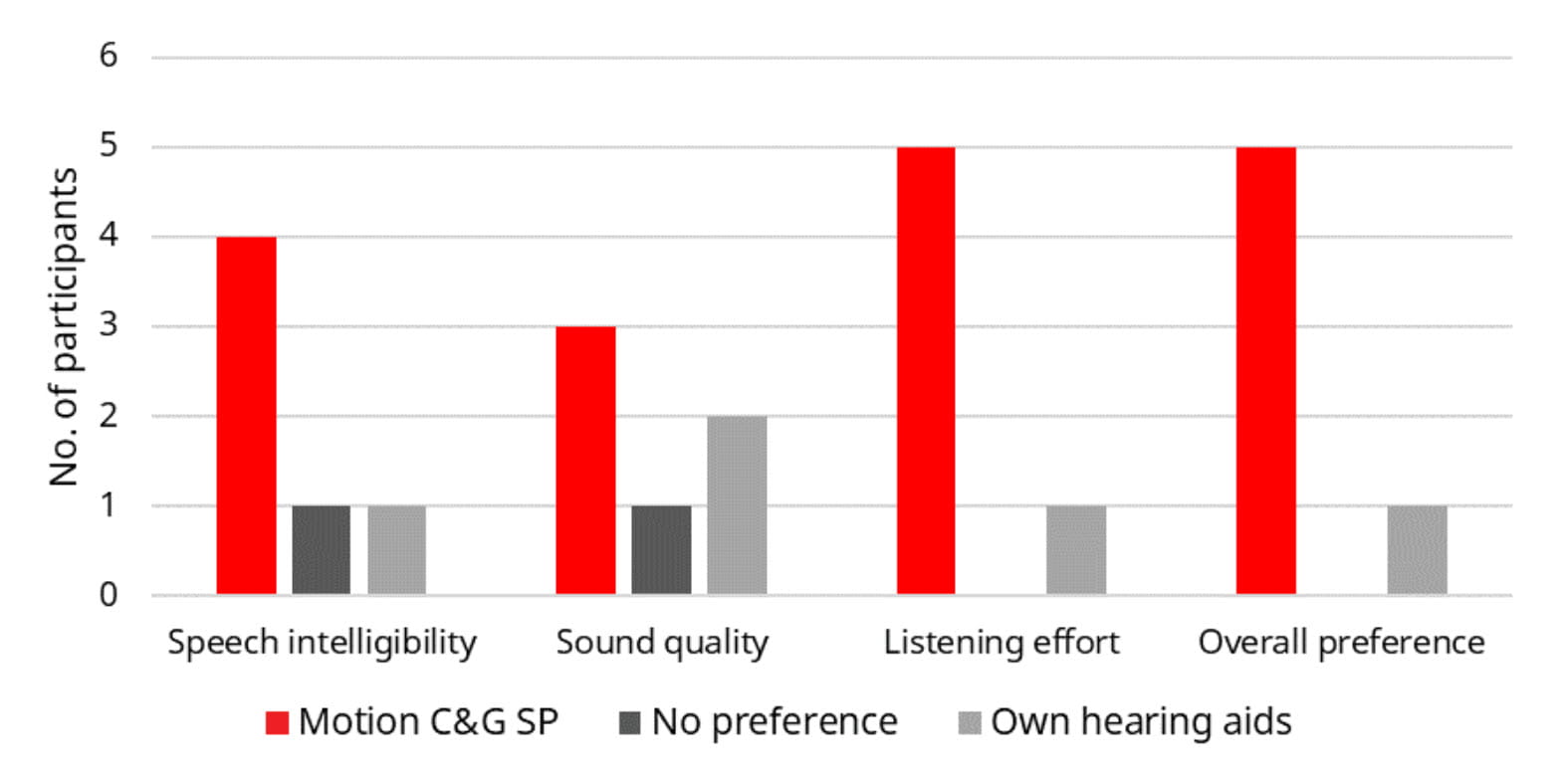
Figure 7. Number of participants having a preference for Motion C&G SP or own hearing aids (or no preference) for speech intelligibility, sound quality, listening effort, and the overall listening experience, based on use of the hearing aids in everyday life.
The real-life perceived speech intelligibility benefit indicated in Figure 7 is in line with results from an independent study performed in the lab at Hörzentrum Oldenburg, Germany. This study was also affected by the pandemic, but it was possible to run a speech intelligibility test on eight participants with severe-profound hearing loss. The mean age of the participants was 71.0 years and the mean PTA4 hearing threshold was 75.9 dB HL.
The purpose of the study was to compare the Signia “More Compressive” fitting strategy with that used in a high-end Super Power device from a competitor, here referred to as Brand A. Both the Signia device and the Brand A device were fitted bilaterally using the respective proprietary fitting rationale. The participants completed the Oldenburger Satztest (OLSA; Wagener et al., 1999) wearing the two pairs of devices in a counterbalanced order. In the test, participants listened to sentences from the front while a constant noise at 65 dB SPL was presented from the back. The level of the speech was adjusted adaptively based on the participant’s ability to repeat the sentences, and the result, the speech reception threshold (SRT), was calculated as the signal-to-noise ratio (SNR) where 50% of the words could be repeated correctly. The results obtained with Signia and Brand A are shown in the box plot in Figure 8.
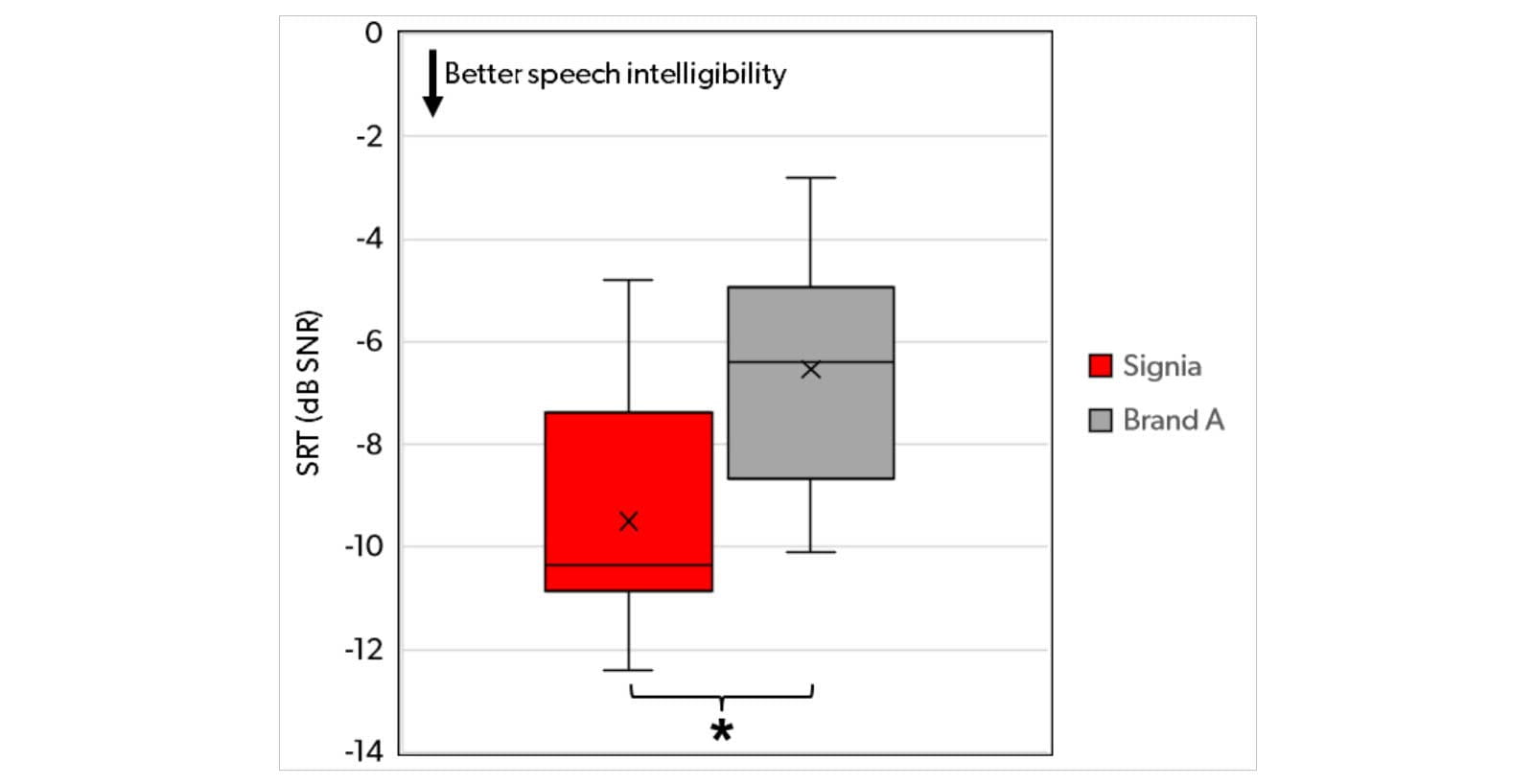
Figure 8. Distribution of individual SRTs for Signia and Brand A, for the participants in the OLSA speech intelligibility test with speech presented from the front and noise presented from the back. Boxes indicate the 25th, 50th (median) and 75th percentiles (quartiles), while the whiskers indicate the minimum and maximum values observed. Mean SRTs are indicated by an “x”.
Figure 8 shows substantially better performance (lower SRT) with the Signia device than with the Brand A device. The mean difference is almost 3 dB, and it is statistically significant according to a t-test (t = 4.66, p = .0023). Furthermore, it can be observed that the median SRT for the Signia device is lower than the minimum SRT (best performance) obtained with the Brand A device. That is, half of the participants fitted with Signia performed better than the best performing participant fitted with Brand A. In the given test setup where the distracting noise was presented from the back, the result shown in Figure 8 highlights the superior performance of the Signia directionality, which is designed to optimize speech intelligibility in the most challenging listening situations.
Conclusion
Fitting hearing instruments to people with severe to profound hearing loss is one of the most demanding challenges in the field. These wearers are completely dependent on their hearing instruments and, both through the physiology of their hearing loss and the long wearing times, extremely sensitive to their hearing instrument performance.
The Signia Xperience platform with the Motion C&G SP device is a true breakthrough for the wearers of power devices. The XFit fitting strategy offers a choice between relevant gain and compression settings for this type of hearing loss, and through the Dynamic Soundscape Processing-slider and the Signia Assistant, the wearer can easily find a preferred balance of sound for best performance.
The innovative Signia Assistant allows the wearer to be more involved in actively shaping the behavior of their own hearing aid, both in everyday life and in communication with the hearing care professional. In addition, Motion C&G SP is the world’s first rechargeable SP-device, and with a wearing time of up to 61 hours, the wearer can feel confident that they will not run out of power throughout their day.
And, our study results indicate that the combination of wise fitting decisions and advanced hearing instrument technology, offers a very successful solution for a large number of people with severe to profound hearing loss.
Download the white paper as a pdf
References
Assmann, P. & Summerfield, Q. 2004. The perception of speech under adverse conditions. New York: Springer Verlag.
Athalye, S. 2010. Factors affecting speech recognition in noise and hearing loss in adults with a wide variety of auditory capabilities. Doctoral dissertation, Institute of sound and vibration Research, University of Southampton.
Convery, E. & Keidser G. 2011. Transitioning hearing aid users with severe and profound loss to a new gain/frequency response: benefit, perception, and acceptance. J Am Acad Audiol, 22(3), 168-180.
Egan, J.P. & Hake, H.W. 1950. On the masking pattern of a simple auditory stimulus. J Acoust Soc Am, 22, 622-630.
Gatehouse, S., Naylor, G. & Elberling, C. 2006. Linear and nonlinear hearing aid fittings - 1. Patterns of benefit. Int J Audiol, 45, 130-152.
Glasberg, B. & Moore, B.C.J. 1985. Auditory filter shapes in subjects with unilateral and bilateral cochlear impairments. J Acoust Soc Am, 79(4), 1020-1033.
Goman, A.M. & Lin, F. 2016. Prevalence of Hearing Loss by Severity in the United States. Am J Public Health, 106(10), 1820-1822.
Høydal EH. 2017 A new own voice processing system for optimizing communication. Hearing Review, 24(11):20-22.
Høydal EH, Fisher R-L, Wolf V, Branda E, Aubreville M. 2020. Empowering the wearer: AI-based Signia Assistant allows individualized hearing care. Hearing Review, 27(7):22-26.
Keidser, G., Dillon, H., Dyrlund, O., Carter, L. & Hartley, D. 2007. Preferred compression ratios in the low and high frequencies by the moderately severe to severe-profound population. J Am Acad Audiol, 18(1), 17-33.
Keidser G., O'Brien A., Carter L., McLelland M. & Yeend I. 2008. Variation in preferred gain with experience for hearing aid users. Int J Audiol, 47, 621-635.
Kemp, T.D. 2002. Otoacoustic emissions, their origin in cochlear function, and use. Br Med Bull, 63, 223-241.
Kishon-Rabin, L., Segal, O. & Algorm, D. 2009. Associations and dissociations between psychoacoustic abilities and speech perception in adolescents with severe-to-profound hearing loss. J Speech Hear Res, 52, 956-972.
Klein, A.J., Mills, J.H. & Adkins, W.Y. 1990. Upward spread of masking, hearing loss, and speech recognition in young and elderly listeners, J Acoust Soc Am, 87, 1266-1271.
Margolis, R.H. & Saly, G.L. 2007. Toward a standard description of hearing loss. Int J Audiol, 46, 746-758.
Moore, B.C.J. 2003. An Introduction to the Psychology of Hearing, 5th ed. Bingley, UK: Emerald.
Moore, B.C.J. 2007. Cochlear Hearing Loss: Physiological, Psychological, and Technical Issues, 2nd ed. Chichester, UK: Wiley.
Moore, B.C.J. & Malicka, A.N. 2013. Cochlear Dead Regions in Adults and Children: Diagnosis and Clinical Implications. Semin Hear, 34(01), 37-50.
Peters, R.W., Moore, B.C.J. & Baer, T. 1998. Speech reception thresholds in noise with and without spectral and temporal dips for hearing-impaired and normally hearing people. J Acoust Soc Am, 103(1), 577-587
Powers T, Froehlich M, Branda E, Weber J. 2018. Clinical study shows significant benefit of own voice processing. Hearing Review, 25(2):30-34.
Stelmachowicz, P.G., Jesteadt, W., Gorga, M.P. & Mott, J. 1985. Speech perception ability and psychophysical tuning curves in hearing-impaired listeners, J Acoust Soc Am, 77, 620-627.
Souza, P., Wright, R. & Bor, S. 2012. Consequences of broad auditory filters for identification of multichannel-compressed vowels. J Speech Lang Hear Res, 55(2), 474-486.
Souza, P. E., Wright, R. A., Blackburn, M. C., Tatman, R., & Gallun, F. J. 2015. Individual sensitivity to spectral and temporal cues in listeners with hearing impairment. J Speech Lang Hear Res, 58(2), 520-534.
Venema, T. 2003. Identifying Cochlear Dead Spots. The Hearing Professional. July/August issue.
Turner, C. W., Souza, P. E. & Forget, L. N. 1995. Use of temporal envelope cues in speech recognition by normal and hearing-impaired listeners. J Acoust Soc Am, 97, 2568-2576.
Turton, L., Souza, P., Thibodeau, L., Hickson, L., Gifford, R., Bird, J., Stropahl, M., Gailey, L., Fulton, B., Scarinci, N., Ekberg, K. & Timmer, B. 2020. Guidelines for Best Practice in the Audiological Management of Adults with Severe and Profound Hearing Loss. Semin Hear, 41(03), 141-246.
Wagener, K., Brand, T., & Kollmeier, B. 1999. Entwicklung und Evaluation eines Satztests fûr die deutsche Sprache. I-III: Design, Optimierung und Evaluation des Oldenburger Satztests (Development and evaluation of a sentence test for the German language. I-III: Design, optimization and evaluation of the Oldenburg sentence test). Z Audiol (Audiol Acoust), 38, 4-15.